Draw it
Autori:
Lena Stanković, učenica III razreda Prve gimnazije u Kragujevcu
Nemanja Obradović, učenik III razreda Gimnazije u Kraljevu
Mentori:
Jelena Marinković, Elektrotehnički fakultet u Beogradu
Novak Stijepić, Elektrotehnički fakultet u Beogradu
Marija Nedeljković, Univerzitet u Kembridžu
Apstrakt
Ovaj rad se bavi problemom prepoznavanja skica nacrtanih slobodnom rukom, što predstavlja izazov zbog apstraktnosti crteža i varijabilnosti stilova korisnika. Istraživanje se fokusira na upoređivanje performansi različitih arhitektura neuronskih mreža: VGG16, AlexNet, MobileNet V3 Small, jednostavne konvolucione mreže (CNN) i rekurentnih mreža (LSTM, BiLSTM) – u zadatku klasifikacije skica. Skup podataka korišćen u radu je Quick, Draw! dataset, kao i dodatni skup prikupljen od korisnika radi testiranja generalizacije. Rezultati pokazuju da konvolucione mreže, posebno AlexNet i MobileNet, značajno nadmašuju rekurentne mreže po tačnosti i efikasnosti, omogućavajući prepoznavanje crteža u realnom vremenu. LSTM i BiLSTM mreže nisu postigle zadovoljavajuću tačnost, dok je VGG16 model zbog niske vrednosti FPS-a nepraktičan za interaktivnu primenu. Doprinos rada ogleda se u detaljnoj analizi performansi različitih arhitektura na realnim i simuliranim podacima, kao i u integraciji najboljeg modela u interaktivnu igricu za prepoznavanje crteža.
Abstract
This study addresses the problem of recognizing freehand-drawn sketches, which is challenging due to the abstract nature of sketches and variability in user drawing styles. The research focuses on comparing the performance of different neural network architectures – VGG16, AlexNet, MobileNet V3 Small, a simple convolutional neural network (CNN), and recurrent networks (LSTM, BiLSTM) – in the task of sketch classification. The Quick, Draw! dataset was used, along with an additional dataset collected from users to test model generalization. Results indicate that convolutional networks, particularly AlexNet and MobileNet, significantly outperform recurrent networks in accuracy and efficiency, enabling real-time sketch recognition. LSTM and BiLSTM networks did not achieve satisfactory accuracy, while the VGG16 model is impractical for interactive use due to its low FPS. The contribution of this work lies in the comprehensive analysis of different architectures on both real and simulated data, as well as the integration of the best-performing model into an interactive sketch recognition game.
Graphical abstract
slika
1. Uvod
Prepoznavanje skica crtanih slobodnom rukom predstavlja izuzetno komplikovan zadatak. Skice mogu biti jako apstraktne, a takođe zavise i od stila osobe koja ih crta, pa ista stvar može biti predstavljena na različite načine. Skice su izvedene samo crno-belim linijama, bez boja, tekstura ili bogatih vizualnih tragova, što može dodatno otežati klasifikaciju prilikom korišćenja unapred treniranih modela. Zbog ovih faktora, čak i ljudima često nije lako da sa sigurnošću prepoznaju šta je nacrtano, posebno ako je crtež minimalan ili stilizovan. Upravo ta apstraktnost i raznovrsnost čine ovaj problem naročito kompleksnim za automatizovano rešavanje.
Draw it je igrica slična igri Pictionary, u kojoj korisnici imaju zadatak da nacrtaju jedan od dva ponuđena pojma u ograničenom vremenu, na što prepoznatljiviji način. Nakon crtanja, računar pokušava da pogodi šta je nacrtano, a korisnik dobija poene za tačne pogotke. Projekat se bazira na implementaciji kompletne igrice, uključujući korisnički interfejs koji omogućava crtanje zadatih pojmova, kao i neuronsku mrežu koja pokušava da prepozna crtež.
Glavni fokus rada, međutim, nije sama igra, već upoređivanje performansi različitih arhitektura neuronskih mreža u zadatku klasifikacije ručno nacrtanih skica. Testirane su konvolucione mreže (AlexNet, VGG16, MobileNet V3 Small i konvoluciona neuronska mreža jednostavne strukture CNN), kao i rekurentne mreže LSTM (Long Short-Term Memory) i BiLSTM (Bidirectional Long Short-Term Memory), sa ciljem da se utvrdi koji model daje najbolje rezultate. Nakon izbora najuspešnijeg modela, on je integrisan u samu igricu.
Jedan od ciljeva projekta bio je i poređenje performansi neuronskih mreža sa rezultatima koje postižu ljudi u istom zadatku. Pošto ovakvo poređenje nije bilo prisutno u dosadašnjim radovima koji su analizirani, ono predstavlja doprinos ovog istraživanja u proceni koliko blizu ljudskom nivou razumevanja može da dođe mašinsko prepoznavanje u kontekstu apstraktnih i pojednostavljenih crteža.
2. Aparatura
Za treniranje modela korišćeni su CPU resursi (Intel Core i5-1235U), koji su bili dovoljni za manje složene arhitekture poput jednostavne CNN mreže i rekurentnih mreža (LSTM i BiLSTM). Ovaj procesor obezbedio je dovoljnu računarsku snagu za osnovno treniranje manjih modela u lokalnim uslovima.
Međutim, za treniranje složenijih modela, kao što su AlexNet, VGG16 i MobileNet V3, korišćeni su GPU resursi dostupni putem Paperspace platforme. U tim slučajevima korišćene su grafičke kartice NVIDIA RTX A4000 i NVIDIA Quadro P4000. RTX A4000 je savremena profesionalna kartica visoke performanse pogodna za rad sa dubokim neuronskim mrežama, dok je Quadro P4000 stariji, ali i dalje pouzdan model za srednje složene arhitekture. Korišćenjem ovih GPU resursa značajno je ubrzan proces treniranja u poređenju sa lokalnim CPU okruženjem.
3. Metod
U okviru ovog rada izvršena je komparativna analiza performansi pet različitih arhitektura neuronskih mreža: VGG16, AlexNet, konvolucione neuronske mreže jednostavne strukture (CNN - Convolutional Neural Network), MobileNet V3 Small i rekurentne neuronske mreže sa dugim kratkoročnim pamćenjem (LSTM i BiLSTM). Nakon toga razvijen je korisnički interfejs i igrica koja integriše izabrani model, omogućavajući korisnicima interaktivno crtanje i prepoznavanje pojmova u realnom vremenu.
3.1. Baza podataka
U projektu je korišćen Quick, Draw! dataset. Ovaj skup podataka sadrži preko 50 miliona crteža, prikupljenih kroz igru Quick, Draw! koju je razvio Google. Crteži su prikupljani tako što su korisnici imali zadatak da nacrtaju određeni predmet ili pojam u roku od 20 sekundi. Svaki crtež je klasifikovan u jednu od 345 različitih kategorija, koje pokrivaju širok spektar svakodnevnih objekata i pojmova. Zbog vremenskog ograničenja, crteži su često brzo i pojednostavljeno nacrtani, što donosi raznovrsnost stilova i nivoa detalja. Ovaj dataset je veoma koristan za istraživanje u oblasti prepoznavanja rukom crtane skice i generisanja crteža.
3.1.1. Priprema podataka za konvolucione neuronske mreže
Korišćena je Simplified Drawing Files verzija dataseta Quick, Draw!, koja sadrži podatke u formatu .ndjson, pri čemu svaki fajl odgovara jednoj klasi crteža, dok svaka linija unutar fajla predstavlja jedan uzorak te klase. Iz svakog uzorka izdvojene su sekvence x i y koordinata koje opisuju poteze korisnika tokom crtanja. Na osnovu tih koordinata rekonstruisani su crteži prikazivanjem poteza kao crnih linija na beloj pozadini. Svaki crtež konvertovan je u sliku dimenzija 256×256 piksela, kao što se može videti na slici 1, čime je omogućen direktan ulaz u konvolutivne neuronske mreže.
Slika 1. Primer slike iz Quick, Draw! dataseta
Nakon generisanja, slike su podeljene u tri skupa: jedan sa 3 klase po 1000 slika, drugi sa 10 klasa po 5000 slika i treći sa 25 klasa po 10 000 slika. Ova struktura omogućava testiranje modela u uslovima različite složenosti klasifikacije.
3.1.2. Priprema podataka za rekurentnu neuronsku mrežu
Korišćena je raw verzija Quick, Draw! skupa podataka, koja sadrži dodatne informacije uključujući i vremenske oznake. Svaki crtež je predstavljen kao niz poteza, gde je svaki potez trostruka sekvenca x, y i t vrednosti. Ove podatke smo transformisali u oblik [[x0, y0, t0], [x1, y1, t1], …, [xn, yn, tn]], što omogućava upotrebu vremenske dinamike u modelima poput LSTM-a. Takođe je kreirana i verzija sa vremenskim razlikama između podataka Δt, kako bi se ispitalo koja reprezentacija daje bolje rezultate.
Da bi svi podaci imali jednaku dužinu, primenjen je postupak popunjavanja sekvenci (padding), kojim su kraće sekvence popunjene nulama do maksimalne dužine. Korišćena je i funkcija objedinjavanja serija (collate funkction), koja primenjuje popunjavanje sekvenci i formira tenzore odgovarajućih dimenzija.
Ovi podaci su, kao i slike, podeljeni u tri skupa: 3 klase sa po 1000 primera, 10 klasa sa po 5000 i 25 klasa sa po 10 000 primera.
3.1.3. Kreiranje novog dataset-a
Kako bi se testirali modeli na skupu podataka koji nije potpuno isti kao Quick, Draw! dataset koji je korišćen za treniranje modela, napravljen je dataset koji sadrži crteže nacrtane od strane drugih ljudi koje smo mi prikupili. Na ovom skupu testiran je odabrani model kako bi se procenilo da li njegova tačnost omogućava upotrebu u realnom vremenu, tj. da li model može pouzdano prepoznavati crteže dok se crtaju. Kreirani skup ima 10 klasa. Primeri slika iz dataseta nalaze se na slici 2.

Slika 2. Primeri slika iz kreiranog dataseta
3.2. VGG16
Korišćena je VGG16 arhitektura, duboka konvoluciona mreža sa 16 slojeva koja koristi male filtere dimenzija 3×3 za efikasnu ekstrakciju karakteristika. Na ImageNet datasetu, VGG16 postiže top-1 tačnost od oko 71.5% i top-5 tačnost od približno 89.8% 1, što je predstavljalo značajan pomak u oblasti klasifikacije slika. Ovaj model je izabran zbog svoje široke primene i uspešnosti u relevantnim referentnim radovima koji se bave klasifikacijom crteža, kao što su radovi From photos to sketches 2 i Pictionary-Style Word Guessing on Hand-Drawn Object Sketches: Dataset, Analysis and Deep Network Models 3. Mreža je korišćena u režimu dotreniravanja (fine-tuning), pri čemu su svi konvolucioni slojevi zamrznuti, a treniran je samo klasifikacioni deo modela kako bi se prilagodio novim klasama i ulaznim slikama.
Ulazne slike su prethodno skalirane na dimenzije 224×224 piksela, što je neophodno za kompatibilnost sa VGG16 arhitekturom. Pored toga, slike su prošle dodatnu obradu koja se sastojala od invertovanja boja i dilatacije linija radi poboljšanja vidljivosti poteza. Na kraju, izvršena je i normalizacija vrednosti piksela kako bi distribucija ulaza odgovarala statistici originalnog ImageNet skupa.
Trening za skup sa 3 klase izvršen je lokalno. Model je treniran koristeći sledeće hiperparametre: broj epoha je bio 10, batch size 64, learning rate 0.001, SGD optimizer i CrossEntropyLoss funkcija.
Za veći skup od 10 klasa trening bio izveden na A4000 GPU putem Paperspace platforme. Trening za 10 klasa trajao je približno 150 minuta. Model je treniran koristeći sledeće hiperparametre: broj epoha je bio 15, batch size 64, learning rate 0.001, SGD optimizer i CrossEntropyLoss funkcija.
3.3. AlexNet
Druga arhitektura koja je korišćena bila je AlexNet 4 arhitektura, duboka konvoluciona mreža sa 8 slojeva koja koristi veće filtere i max-pooling slojeve za izdvajanje značajnih karakteristika iz slike. Ovaj model je bio jedan od prvih koji je pokazao veliku efikasnost u prepoznavanju slika i značajno je uticao na razvoj savremenih metoda u oblasti dubokog učenja. Ovaj model je izabran zbog svoje široke primene i velike uspešnosti u većini referentnih radova koji se bave klasifikacijom crteža, kao što je rad DeepSketch 5. Mreža je trenirana od nulte tačke, tako da su svi slojevi podešavani kako bi se model prilagodio novim klasama i ulaznim slikama.
Ulazne slike su prethodno skalirane na dimenzije 227×227 piksela, što je neophodno kako bi se prilagodio ulaz za AlexNet arhitekturu. Izvršena je i normalizacija koja je važna kako bi se vrednosti piksela nalazile u ujednačenom rasponu, što omogućava stabilnije treniranje modela. Na jednom od skupova podataka primenjene su dodatne transformacije: dilatacija i invertovanje slika. Dilatacijom se objekti na slici proširuju dodavanjem piksela uz ivice, dok je invertovanje proces zamene svetlih i tamnih tonova tako da se bele oblasti pretvaraju u crne i obrnuto. Zatim su upoređeni rezultati mreže trenirane na tako obrađenim slikama i mreže trenirane na originalnim slikama bez tih transformacija. Pošto su bez dodatnih obrada postignuti bolji rezultati u pogledu tačnosti i ostalih evaluacionih metrika, dalje treniranje i unapređivanje modela su izvođeni sa originalnim slikama na kojima su bili izvršeni samo skaliranje i normalizacija.
Trening za skup sa 3 klase izvršen je lokalno. Model je treniran koristeći sledeće hiperparametre: broj epoha je bio 10, batch size 64, learning rate 0.001, SGD optimizer i CrossEntropyLoss funkcija.
Za veći skup od 10 klasa trening je prvo bio izveden lokalno, a kasnije i na A4000 GPU putem Paperspace platforme. Trening za 10 klasa trajao je malo manje od dva sata. Model je treniran koristeći sledeće hiperparametre: broj epoha je bio 15, batch size 64, learning rate 0.001, SGD optimizer i CrossEntropyLoss funkcija.
Trening na najvećem korišćenom skupu podataka, 25 klasa sa po 10000 slika, bio je izvršen na grafičkoj kartici NVIDIA RTX A4000, na kojoj je jedna epoha trajala približno sat vremena. Model je treniran koristeći sledeće hiperparametre: broj epoha je bio 15, batch size 64, learning rate 0.001, SGD optimizer i CrossEntropyLoss funkcija.
3.4. CNN - konvoluciona neuronska mreža jednostavne strukture
Pored poznatijih arhitektura, korišćena je i jedna jednostavnija konvoluciona mreža. Cilj njene implementacije bio je da se uporede performanse manje, brže mreže sa složenijim i dubljim modelima. Ova mreža ima znatno manji broj parametara, pa se očekivala niža tačnost, ali i znatno manja računarska složenost, brže treniranje i veći broj frejmova u sekundi (FPS - frames per second) tokom izvođenja. Arhitektura mreže preuzeta je iz referentnog rada Simple Convolutional Neural Network on Image Classification 6, a njen prikaz dat je na slici 3.
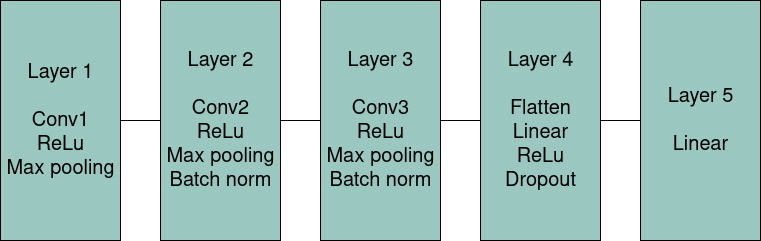
Slika 3. Arhitektura konvolucione mreže
Korišćena konvoluciona neuronska mreža sastoji se od tri konvoluciona sloja i dva fully connected sloja. Prvi konvolucioni sloj primenjuje 64 filtera dimenzije 5×5 sa ReLU aktivacijom, nakon čega sledi max-pooling. Drugi i treći konvolucioni slojevi imaju istu strukturu kao prvi, ali dodatno uključuju i batch normalization, što doprinosi stabilnijem treniranju. Nakon trećeg konvolucionog sloja, izlaz se prolazi kroz flatten operaciju, kojom se višedimenzionalni tenzor pretvara u jednodimenzionalni vektor, neophodan za rad fully connected slojeva. Prosleđuje se kroz fully connected sloj sa 500 neurona, ReLU aktivacijom i dropout regularizacijom (0.5). Na kraju, poslednji linearni sloj mapira aktivacije na broj izlaznih klasa. Ova arhitektura je kompaktna i brza, a istovremeno dovoljno izražajna da može efikasno učiti reprezentacije iz ulaznih slika dimenzije 32×32.
Ulazne slike su prethodno skalirane na dimenzije 32×32 piksela, što dodatno uprošćava ulazne podatke, smanjuje vreme treninga i povećava fps. Takođe je izvršena normalizacija piksela kako bi se obezbedio stabilniji i efikasniji proces treniranja modela od nule.
Model je na trening setovima od 3 i 10 klasa treniran lokalno. Trening je obavljen u 10 epoha za dataset od 3 klase, odnosno 12 epoha za dataset od 10 klasa. Drugi hiperparametri su bili: batch size 64, learning rate 0.01, SGD optimizer i CrossEntropyLoss funkcija. Trening na setu od 3 klase trajao je manje od minut, dok je na setu od 10 klasa trajao nešto manje od 10 minuta.
Treniranje modela je na skupu sa 25 klasa izvršeno na A4000 GPU putem Paperspace platforme. Treniran je koristeći sledeće hiperparametre: broj epoha je bio 20, batch size 64, learning rate 0.01, SGD optimizer i CrossEntropyLoss funkcija. Trening je trajao manje od pola sata.
3.5. MobileNet V3 small
MobileNet V3 predstavlja efikasnu konvolucionu arhitekturu koja kombinuje visoke performanse sa malim brojem parametara 7. Za ovaj projekat korišćena je verzija MobileNet V3 Small. Ova arhitektura koristi kombinaciju depthwise separable konvolucija, Squeeze-and-Excitation modula i hard-swish aktivacija, čime postiže dobar balans između tačnosti i efikasnosti. Izabrana je verzija Small zbog njene posebno male složenosti, što je čini pogodnom za primene gde je brzina izvođenja važna, kao što je interaktivna igrica u realnom vremenu. MobileNet arhitektura korišćena je u radu Pocket-Sized AI 8. Iako je manja od MobileNet V3 Large verzije, zadržava dovoljno izražajne moći da se koristi za klasifikaciju crteža uz znatno manji broj parametara i veći FPS. Mreža je korišćena u režimu dotreniravanja (fine-tuning), pri čemu su svi konvolucioni slojevi zamrznuti, a treniran je samo klasifikacioni deo modela kako bi se prilagodio novim klasama i ulaznim slikama.
Mreža MobileNet V3 Small trenirana je u režimu dotreniravanja. Trening za skup sa 3 i 10 klasa izvršen je lokalno. Model je, na skupu sa tri klase, treniran koristeći sledeće hiperparametre: broj epoha je bio 10, batch size 64, learning rate 0.001, SGD optimizer i CrossEntropyLoss funkcija. Zbog izraženog overfitting-a, posle svake epohe čuvani su parametri modela, za koji su kasnije izračunate metrike na testnom skupu. Za dalju upotrebu izabran je model sa najvišim postignutim rezultatima na testnim podacima. Najbolji rezultati postignuti su prilikom korišćenja modela nakon druge epohe treniranja.
Model je, na skupu sa deset klasa, treniran koristeći sledeće hiperparametre: broj epoha je bio 15, batch size 64, learning rate 0.01, SGD optimizer i CrossEntropyLoss funkcija. Kao i kod treninga na 3 klase, čuvani su modeli posle svake epohe zbog izraženog overfitting-a. Najbolji rezultati postignuti su prilikom korišćenja modela nakon desete epohe treniranja.
Treniranje modela je na skupu sa 25 klasa izvršeno na A4000 GPU putem Paperspace platforme. Treniran je koristeći sledeće hiperparametre: broj epoha je bio 30, batch size 64, learning rate 0.01, SGD optimizer i CrossEntropyLoss funkcija.
3.6. RNN
Rekurentne neuronske mreže (RNN) predstavljaju arhitekturu prilagođenu obradi sekvencijalnih podataka, jer imaju sposobnost da zadrže informacije iz prethodnih koraka kroz skrivena stanja. Međutim, klasične RNN imaju problem dugoročnog pamćenja zbog pojava poput nestajućih gradijenata. Zbog toga se često koristi LSTM (Long Short-Term Memory), koji kroz posebnu strukturu sačinjenu od ulazne, izlazne i forget kapije uspešnije čuva i prenosi informacije kroz duže sekvence. Ova arhitektura se pokazala kao efikasna u zadacima koji uključuju vremenske tokove ili nizove koordinata, kao što je slučaj sa podacima o potezima u crtežima.
3.6.1. LSTM
U referentnom radu Sketch Classification with Neural Networks. A Comparative Study of CNN and RNN on the Quick, Draw! data set 9 LSTM mreža se pokazala uspešnijom od konvolucione arhitekture, dok se u drugom radu, Sketch Recognition for Interactive Game Experiences Using Neural Networks 10, pokazala nešto lošije. U više radova, korišćene su i bidirekcione LSTM (BiLSTM) mreže, koje omogućavaju analizu sekvence u oba smera i time poboljšavaju kontekstualno razumevanje podataka. Ni u jednom od ovih radova vreme nije bilo uključeno kao ulazna karakteristika, zbog čega smo odlučili da ispitamo uticaj vremenske komponente. U našim modelima dodavali smo i apsolutno vreme (t) u odnosu na početni trenutak, kao i vremenske razlike (Δt) kao dodatne ulaze i uporedili rezultate modela sa tim informacijama.
LSTM mreža je u početku trenirana na skupu sa samo dve klase radi testiranja osnovnih performansi. Prvobitna implementacija obuhvatala je jedan LSTM sloj, ali model nije pokazivao sposobnost učenja i tačnost je ostajala oko 50% tokom svih epoha, čak i pri pokušaju overfittinga na manjem skupu podataka. Zbog toga je odlučeno da se koristi složenija arhitektura iz referentnog rada Sketch Classification with Neural Networks. A Comparative Study of CNN and RNN on the Quick, Draw! data set 9, koja je ranije pokazala dobre rezultate u zadatku prepoznavanja crteža. Nakon te izmene, model je počeo da uči, pa je treniran na skupu sa tri klase tokom 100 epoha. Najveća tačnost postignuta je u 45. epohi, nakon čega nije bilo značajnijeg napretka, kada je model krenuo da uči napamet slike iz trening seta.
3.6.2. BiLSTM
BiLSTM mreža je varijanta LSTM mreže koja omogućava da se sekvence obrađuju u oba smera, unapred i unazad. U našem radu korišćena je BiLSTM mreža sa jednim bidirekcionim LSTM slojem. Ova arhitektura odabrana je kako bi se uporedila sa jednostavnijom LSTM mrežom, s obzirom na to da su BiLSTM modeli često korišćeni u sličnim zadacima. Model je treniran tokom 100 epoha, a najbolji rezultat postignut je u 81. epohi, nakon čega je došlo do overfittinga.
3.7. Korisnički interfejs
Korisnički interfejs (UI - User interface) je razvijen korišćenjem biblioteke PyQt5 u Python okruženju. Prva implementacija interfejsa namenjena je eksperimentu za poređenje performansi modela i ljudskih odgovora. U toj verziji implementirana je jednostavna bela površina za crtanje, dok model pokušava da prepozna sadržaj crteža bez prethodno zadanog pojma.
Na osnovu ove verzije razvijena je i prva funkcionalna verzija igrice. U njoj se koristi AlexNet model treniran lokalno na 10 klasa. Ova verzija predstavlja prošireni sistem u kojem se korisniku zadaje pojam, a zatim crta dok model ne pogodi, korisnik ne odluči da preskoči ili istekne vremensko ograničenje od 20 sekundi po crtežu. Igra traje ukupno 60 sekundi, a cilj je ostvariti što više poena. Poeni se dodeljuju kada model tačno pogodi pojam, s tim da se brže pogađanje nagrađuje većim brojem poena.
Plan za dalji razvoj podrazumeva prenos igre na HTML interfejs, nakon odabira konačnog modela. Trenutna implementacija UI-ja prilagođena je isključivo konvolucionim mrežama, dok bi za rekurentne bilo potrebno dodatno razviti sistem za prikupljanje vremenski zavisnih podataka o potezima korisnika.
3.8. Metrike
3.8.1. Tačnost, preciznost, odziv i f1 skor
Tačnost (accuracy) predstavlja procenat ispravno klasifikovanih primera u odnosu na ukupan broj uzoraka, pružajući opštu ocenu uspešnosti modela. Preciznost (precision) meri koliko su pozitivne predikcije modela tačne, odnosno koliki je udeo istinski pozitivnih među svim primerima koje je model označio kao pozitivne. Odziv (recall) pokazuje koliko model uspešno detektuje sve stvarno pozitivne slučajeve, naglašavajući sposobnost modela da ne propusti relevantne primere.
Tačnost = (TP + TN) / (TP + TN + FP + FN)
Preciznost = TP / (TP + FP)
Odziv = TP / (TP + FN)
F1 skor predstavlja harmonijsku sredinu preciznosti i odziva, kombinujući obe metrike u jednu vrednost. Ova mera je naročito korisna kada postoji neuravnoteženost klasa, jer pruža balans između preciznosti i odziva, omogućavajući objektivniju procenu performansi modela u takvim uslovima.
F1 skor = 2 * (Precision * Recall) / (Precision + Recall)
3.8.2. Matrice konfuzije
Pored osnovnih metrika, kao što su tačnost, preciznost, odziv i F1 skor, za dublju analizu performansi modela korišćene su i matrice konfuzije. Ove matrice omogućavaju vizuelni prikaz tačnih i pogrešnih klasifikacija za svaku klasu posebno. Na primer, ukoliko model tačno prepozna crtež banane, taj primer se beleži na dijagonali u redu i koloni „banana“. Međutim, ako model greškom klasifikuje crtež banane kao kalendar, taj primer će se pojaviti van dijagonale, u redu „banana“, a u koloni „kalendar“. Na taj način, matrica konfuzije ne samo da prikazuje koliko je model bio tačan, već i koje klase najčešće meša, čime omogućava identifikaciju konkretnih slabosti u klasifikaciji.
3.8.3. ROC kriva
ROC (Receiver Operating Characteristic) kriva predstavlja važan alat za evaluaciju performansi modela za klasifikaciju slika. Ona vizuelno prikazuje sposobnost modela da pravilno razlikuje klase. ROC kriva omogućava procenu uspešnosti modela u različitim uslovima tako što prikazuje odnos između senzitivnosti (TPR - true positive rate) i specifičnosti (FPR - false positive rate) pri različitim pragovima odlučivanja. TPR i FPR se računaju po sledećim formulama:
TPR = TP / (TP + FN)
FPR = FP / (FP + TN)
3.8.4. FPS
FPS predstavlja meru brzine kojom model može da procesuira ulazne podatke i generiše izlaz, odnosno koliko slika u sekundi može da obradi. Ova metrika je posebno važna za aplikacije koje zahtevaju rad u realnom vremenu, gde je brz odgovor neophodan za dobar korisnički doživljaj.
Kako bi model efikasno radio u realnom vremenu, što je jedan od zahteva ovog projekta, meren je FPS za svaku korišćenu mrežu. Na osnovu ovih merenja izabran je model koji pruža najbolji balans između tačnosti i brzine, odnosno koji omogućava optimalan broj frejmova u sekundi za nesmetan rad u realnom vremenu.
4. Rezultati
Trening za LSTM i BiLSTM na 10 i 25 klasa nije izvršen zbog ograničenog raspoloživog vremena. Na osnovu rezultata modela na 3 klase uočeno je da se ove rekurentne mreže značajno lošije pokazuju na ovom zadatku od konvolucionih mreža.
Model VGG16 nije treniran na setu od 25 klasa, jer bi njegovo treniranje na GPU trajalo više od 10 sati. Pored toga, zbog niske vrednosti FPS, ovaj model ne bi bio izabran za finalnu implementaciju.
4.1. Tačnost
| Model | AlexNet | VGG16 | CNN | MobileNet | LSTM | BiLSTM |
|---|---|---|---|---|---|---|
| 3 klase | 94.22 | 98.00 | 84.22 | 90.89 | 68.44 | 69.56 |
| 10 klasa | 95.45 | 98.36 | 85.35 | 90.85 | / | / |
| 25 klasa | 92.59 | / | 91.03 | 94.54 | / | / |
Tabela 1. Uporedni prikaz tačnosti modela
Najveća tačnost na setovima sa 3 i 10 klasa postignuta je korišćenjem konvolucione neuralne mreže VGG16, dok je na skupu od 25 klasa najveća postignuta tačnost bila prilikom korišćenja MobileNet modela.
4.2. Preciznost
| Model | AlexNet | VGG16 | CNN | MobileNet | LSTM | BiLSTM |
|---|---|---|---|---|---|---|
| 3 klase | 94.88 | 98.05 | 88.01 | 90.90 | 71.10 | 69.40 |
| 10 klasa | 95.74 | 98.36 | 86.22 | 91.03 | / | / |
| 25 klasa | 93.06 | / | 91.59 | 94.64 | / | / |
Tabela 2. Uporedni prikaz preciznosti modela
Najveća preciznost na setovima sa 3 i 10 klasa postignuta je korišćenjem mreže VGG16, dok je na skupu od 25 klasa najveća postignuta preciznost bila prilikom korišćenja MobileNet modela.
4.3. Odziv
| Model | AlexNet | VGG16 | CNN | MobileNet | LSTM | BiLSTM |
|---|---|---|---|---|---|---|
| 3 klase | 94.22 | 98.04 | 84.71 | 90.22 | 68.44 | 69.74 |
| 10 klasa | 95.47 | 98.36 | 85.44 | 90.85 | / | / |
| 25 klasa | 92.59 | / | 91.03 | 94.54 | / | / |
Tabela 3. Uporedni prikaz odziva modela
Najveća vrednost odziva na setovima sa 3 i 10 klasa postignuta je korišćenjem mreže VGG16, dok je na skupu od 25 klasa najveća postignuta vrednost odziva bila prilikom korišćenja MobileNet modela.
4.4. F1 skor
| Model | AlexNet | VGG16 | CNN | MobileNet | LSTM | BiLSTM |
|---|---|---|---|---|---|---|
| 3 klase | 94.33 | 98.04 | 84.04 | 90.22 | 68.04 | 69.29 |
| 10 klasa | 95.50 | 98.36 | 85.53 | 90.91 | / | / |
| 25 klasa | 92.68 | / | 91.11 | 94.54 | / | / |
Tabela 4. Uporedni prikaz F1 skorova modela
Najveća vrednost F1 skora na setovima sa 3 i 10 klasa postignuta je korišćenjem mreže VGG16, dok je na skupu od 25 klasa najveća postignuta vrednost F1 skora bila prilikom korišćenja MobileNet modela.
4.5. FPS
| Model | AlexNet | VGG16 | CNN | MobileNet | LSTM | BiLSTM |
|---|---|---|---|---|---|---|
| FPS | 17.95 | 2.37 | 256.03 | 48.84 | 285.66 | 621.53 |
Tabela 5. Uporedni prikaz vrednosti FPS-a modela
Najveća vrednost FPS postignuta je korišćenjem mreže BiLSTM, dok je konvoluciona mreža koja je postigla najveći FPS bila konvoluciona neuronska mreža jednostavne strukture.
4.6. Test na novom skupu podataka
Model je testiran na skupu podataka kreiranom prikupljanjem crteža koje su nacrtali drugi korisnici, kako bi se testirala njegova sposobnost generalizacije na primere koji se razlikuju od Quick, Draw! dataseta korišćenog za treniranje. Za evaluaciju je korišćen AlexNet model.
Na ovom testnom skupu model je postigao tačnost od 74.19%. Detaljnija analiza performansi modela može se videti iz matrice konfuzije, prikazane na slici 4.
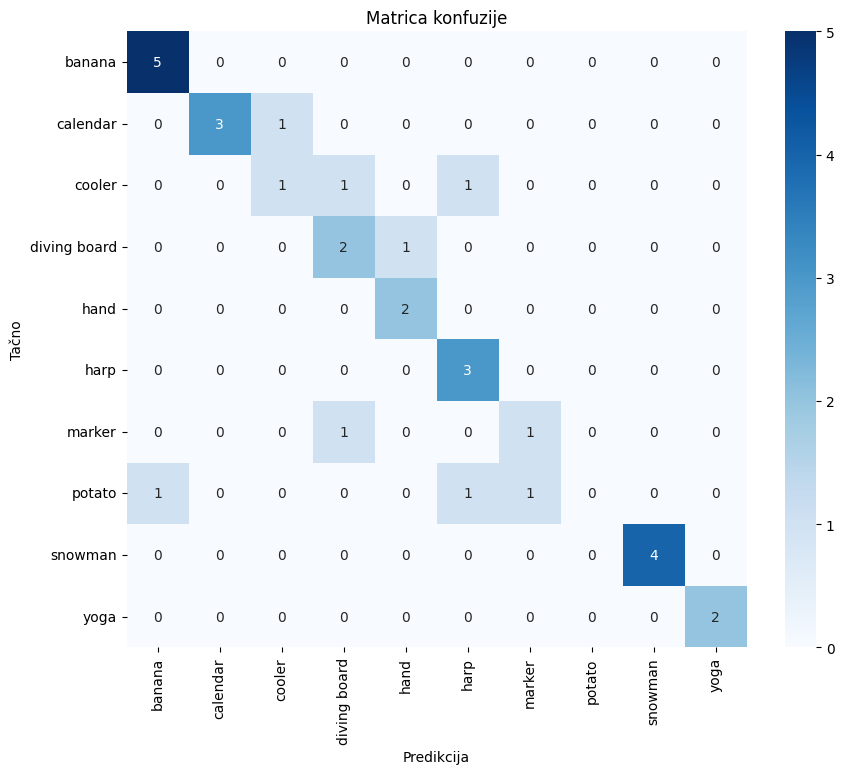
Slika 4. Matrica konfuzije na kreiranom skupu podataka
5. Diskusija
Tačnost postignuta rekurentnim mrežama bila je primetno niža u odnosu na rezultate prikazane u referentnim radovima. Jedan od mogućih razloga za to jeste razlika u tipu ulaznih podataka. Za razliku od ranijih radova, u ovom istraživanju korišćeni su i vremenski podaci, apsolutno vreme ili razlika između poteza, kao dodatni fičeri. Ipak, pokazalo se da vreme verovatno nije relevantan podatak za prepoznavanje crteža, jer brzina crtanja može značajno varirati među korisnicima i ne mora biti povezana sa oblikom ili sadržajem crteža. Uvođenjem takvog varijabilnog podatka moguće je da je mreža dobila dodatni šum, što je negativno uticalo na učenje i smanjilo ukupnu tačnost klasifikacije.
Budući da VGG16 zbog niske vrednosti FPS-a nije razmatran za finalnu implementaciju, fokus je na metrikama ostalih mreža. Na setovima od 3 i 10 klasa najbolje rezultate ostvaruje AlexNet, dok MobileNet postiže najbolje rezultate na skupu od 25 klasa. Može se pretpostaviti da razlika između rezultata ova dva modela nastaje zato što MobileNet brzo overfituje na setovima sa manjim brojem klasa, zbog čega se AlexNet bolje ponaša u tim uslovima.
Analiza matrice konfuzije pokazuje da model nikada ne predviđa klasu ‘krompir’. Detaljnija analiza primeraka iz klase ‘krompir’ u Quick, Draw! dataset-u ukazuje da većina crteža dodiruje ivice okvira za crtanje, što nije očekivano ponašanje korisnika. Ova pretpostavka je kasnije potvrđena proverom u programu koji radi u realnom vremenu sa 10 klasa.
6. Zaključak
Zaključuje se da se na ovom zadatku konvolucione mreže značajno bolje pokazuju od rekurentnih. Postignuti rezultati pokazuju da AlexNet i MobileNet mogu pouzdano prepoznavati crteže u realnom vremenu, dok modeli poput VGG16 nisu praktični zbog niskog FPS-a, a LSTM i BiLSTM ne postižu zadovoljavajuću tačnost.
Doprinos ovog rada ogleda se u analizi performansi različitih arhitektura na originalnom Quick, Draw! dataset-u, kao i na dodatnom dataset-u prikupljenom od korisnika, čime je testirana sposobnost generalizacije modela na nove, realistične podatke.
7. Dalji rad
Dalji rad uključuje dopunu evaluacionih metrika, iscrtavanje ROC krive, kao i poređenje performansi modela sa ljudskim odgovorima. Planirano je i kreiranje igre koja bi radila sa 25 klasa u Pythonu, a zatim i završetak prenosa igre na HTML interfejs kako bi je korisnici mogli koristiti, čime bi se prikupljali dodatni istraživački podaci.
Poređenje performansi modela sa ljudskim odgovorima radilo bi se tako što bi se kreirali snimci koji simuliraju igranje igrice, a zatim bi ti snimci bili dati i modelu i korisnicima radi predviđanja pojma. Bio bi upoređivan broj pokušaja ili vreme potrebno da se dođe do tačne predikcije.
8. Literatura
-
K. Simonyan, A. Zisserman, “Very Deep Convolutional Networks for Large-Scale Image Recognition”, 2015, arXiv preprint arXiv:1409.1556. ↩︎
-
J. J D Singer, K. Seeliger, T. C Kietzmann and M. N Hebart, “From photos to sketches - how humans and deep neural networks process objects across different levels of visual abstraction.” 2022 Journal of Vision February 2022, Vol.22, 4. doi: 10.1167/jov.22.2.4. ↩︎
-
R. K. Sarvadevabhatla, S. Surya, T. Mittal and R. V. Babu, „Pictionary-Style Word Guessing on Hand-Drawn Object Sketches: Dataset, Analysis and Deep Network Models,” in IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 42, no. 1, pp. 221-231, 1 Jan. 2020, doi: 10.1109/TPAMI.2018.2877996. ↩︎
-
A. Krizhevsky, I. Sutskever, G. E. Hinton, “ImageNet Classification with Deep Convolutional Neural Networks”, 2012, Advances in Neural Information Processing Systems (NeurIPS). ↩︎
-
O. Seddati, S. Dupont and S. Mahmoudi, „DeepSketch: Deep convolutional neural networks for sketch recognition and similarity search,” 2015 13th International Workshop on Content-Based Multimedia Indexing (CBMI), Prague, Czech Republic, 2015, pp. 1-6, doi: 10.1109/CBMI.2015.7153606. ↩︎
-
T. Guo, J. Dong, H. Li and Y. Gao, „Simple convolutional neural network on image classification,” 2017 IEEE 2nd International Conference on Big Data Analysis (ICBDA), Beijing, China, 2017, pp. 721-724, doi: 10.1109/ICBDA.2017.8078730. ↩︎
-
A. Howard, M. Sandler, B. Chen, W. Wang, L.-C. Chen, M. Tan, G. Chu, A. Vasudevan, Y. Zhu, R. Pang, V. Vasudevan, Q. Le, H. Adam, “Searching for MobileNetV3”, 2019, Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). ↩︎
-
N. More, S. Patil, A. Pasi,B. Palkar, V. Venkatramanan, P. Mishra, „Pocket-Sized AI: Evaluating Lightweight CNNs for Real-Time Sketch Detection” 2025 K.J.Somaiya School of engineering, Somaiya Vidyavihar University, Vidyavihar, Mumbai, India, pp. 648-658 ↩︎
-
M. Andersson, M. Arvola, S. Hedar, „Sketch Classification with Neural Networks - A
Comparative Study of CNN and RNN on the Quick, Draw! data set” 2018 Uppsala University, Uppsala Municipality, Sweden ↩︎ ↩︎ -
E. Hilal Korkut, E. Surer, “Sketch Recognition for Interactive Game Experiences Using Neural Networks” 2023 Department of Modeling and Simulation, Graduate School of Informatics, Middle East Technical University, 06800 Ankara, Turkey ↩︎